이번 글에서는 C++ 개발자로써 Data-Oriented Design을 세상에 소개한 Mike Acton이라는 사람의 유명한 CppCon 발표를 다뤄보고자 한다.

발표자 Mike Acton은 2014년 당시에 Insomniac Games의 엔진 디렉터였으며, 플레이스테이션을 비롯한 여러 콘솔 디바이스에서 게임을 구현하기 위해 다양한 노력들을 해왔다. 이후 Unity3d Engine의 기술 디렉터를 역임하였으며, 이 시기에 Unity Engine에 ECS(Entity Component System)이라는 Data-Oriented Design GameObject 시스템 개발을 주도한 것으로 알려져 있다.
2014년도에 그가 CppCon에서 발표한 “Data-Oriented Design and C++”는 지금까지도 많은 사람들에게 회자되고 있는 명강연이다. 개인적으로도 약 1시간 30분 가량의 발표동안 단 한순간도 눈을 뗄 수가 없었다. 너도나도 C++는 로우레벨 언어라고들은 쉽게 말하지만, 정말 C++로 로우레벨을 다룬다는 것이 무엇인지 이 발표에서는 제대로 보여주며, 이를 통해 "Data-Oriented Design"의 덕목이 어떻게 실현될 수 있는지를 역설한다.
1. Data-Oriented라는 것이 실제로 무엇인가?
그는 가장 먼저 Data-Oriented Design principle들을 다음과 같이 소개했다.
The purpose of all programs, and all parts of those programs, is to transform data from one form to another.
Mike는 먼저 프로그램이라는 개념에 대해서 이렇게 정의하였다. 요컨대 이런 것이다.
- 계산기란 수식 데이터를 정답 데이터로 변환하는 프로그램이다.
- 게임이란 게임 속 세상을 구성하는 데이터와 사용자의 입력 데이터를 화면 데이터으로 1초에 60번씩 변환하는 프로그램이다.
- 운영체제란 메모리에 있는 데이터와 사용자의 입력데이터를, 메모리에 저장될 또 다른 데이터와 화면 출력으로 컴퓨터가 꺼질 때까지 변환하는 프로그램이다.
If you don't understand the data you don't understand the problem.
데이터를 이해하지 못하면 문제를 이해하지 못한 것이라니 실로 데이터 중심의 사고가 아닐 수 없다.
반대로 말해 문제를 제대로 이해하려면 데이터를 먼저 잘 이해해야 하며 데이터가 다르다면 문제 역시 다른 것이고, 이에따라 문제가 서로 다르다면 솔루션 역시 서로 다르다고 설명했다.
이때 어떤 문제에 대한 솔루션 비용(Cost of solving problem)을 이해하지 못했다면, 그것은 문제를 이해한 것이 아니며, 하드웨어를 이해하지 못한다면 문제의 솔루션 비용도 판단할 수 없다고 말했다.
요약하자면, Data-Oriented design으로 문제를 푼다는 것은 데이터와, 해결하려는 문제와, 해법의 비용과, 해법을 수행하는 환경 모든 것에 대한 이해가 수반되어야 한다. 이로써 사용성, 유지보수성, 디버깅 용이성들도 결국엔 데이터와 연관된 문제라는 것이다.
Rule of Thumbs
1. 데이터란 하나가 있다면, 여러 개도 있다. 항상 시간 축 위에서 고려하기 위해 노력하라. Context를 더 많이 알 수록 더 나은 솔루션을 얻을 수 있다. 필요한 데이터를 무시하지 마라.
2. 즉각적인 I/O나 프로그램의 Pre-built data에서부터 하드디스크같은 원본 데이터에 접근하는데에는 모두 각기다른 시간이 소모됨을 유의해라.
3. Reason must prevail. 소프트웨어란 컴퓨터과학 연구실 어느 열정어린 박사의 마법같은 환상 위에서 실행되는 것이 아니라, 철저히 현실 속에서 현실의 데이터를 다루는 것이다.
2. 흔히 알려진 세가지 거짓말
Mike는 우리가 경계하고 경계해야할 프로그래머 업계에 널리 퍼진 3가지 거짓말을 다음과 같이 정의했다.

거짓말 1. 소프트웨어는 플랫폼이다.
하드웨어야말로 플랫폼이다. 같은 문제에 대해 구글의 거대한 서버팜과 손바닥만한 조그마한 아두이노가 같은 솔루션을 취할 수는 없다. 하드웨어마다 서로 다른 물리적인 제약과 유한한 자원이 있는데 어떠한 소프트웨어 솔루션도 이로부터 독립적일 수는 없다. 현실이란 당신의 이론적이고 추상적인 문제에서 맞딱드릴 장애물 같은 것이 아니다. 현실이 문제 그 자체다.
거짓말 2. 코드는 실제 세계에 대한 모델링 기반으로 설계되어야 한다
실제 세계를 모델링 한다는 것은 대개 다루려는 실제 데이터를 뒤로 숨기는 것이다. 그런데 이는 1) 프로그램이 좋은 유지보수성을 갖게 만드는 것과 2) 문제를 풀기위해 데이터의 속성을 잘 이해하는 것의 차이를 쉽게 혼동하게 만든다. 개념적으로 깔끔하게 추상화하여 모델링을 잘하면 1)을 성공적으로 달성할 수 있겠지만, 그것이 반대로 2)를 굉장히 어렵게 만들 수도 있다는 것이다.
예를 들어 chair에 대해 모델링 한다면, 가장 기본이 되는 chair로부터 여러가지가 파생될 것이다. 하지만 의자라는 개념 그 자체는 문제도 아니고 데이터도 아니다. 다뤄야하는 실제 문제는 그보다는 ‘부서지는 의자’, ‘앉을 수 있는 의자’, ‘장식용 의자’ 등등을 구분하여 이를 각각 알맞게 처리하는 것이며, 이 때 chair라는 공통 속성이 있다는 것은 그다지 유용한 정보가 아니다.
모델링은 대개 문제를 보다 단순한 개념으로 이상화하고자 시도하지만, 문제를 문제 그 자체보다 더 단순하게 만들 수는 없다. 모델링은 좋은 비유, 좋은 스토리 텔링이 될 수는 있지만 문제 해결에서도 무조건 좋지만은 않다.
거짓말 3. 코드는 데이터보다 중요하다.
코드는 단지 어떤 데이터를 다른 어떤 데이터로 바꾸기 위함이 목적이다. 여기서 중요한 것이 과연 코드일까 데이터일까? 프로그래머가 책임감을 가져야 하는 것은 코드일까 코드가 만들어내는 데이터일까?
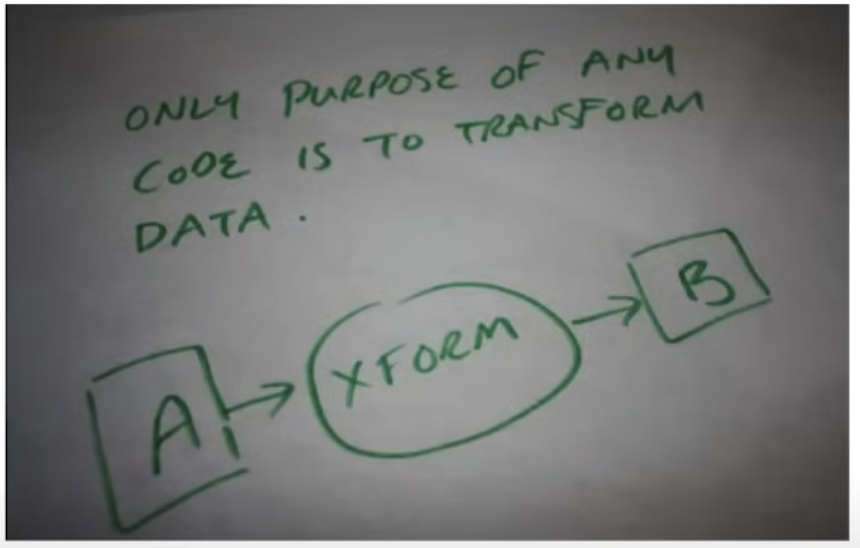

그래서 이를 잘 구분하기 위해서는 가장 먼저 다뤄야할 데이터가 무엇인가에 대해 정확히 아는 것이 중요하다고 말한다. 따라서 코드는 주어진 제약조건 속에서 데이터를 잘 가공하기 위한 도구 그 이상 그 이하도 아니라고 강하게 주장한다.

이어서 Mike는 이 세 가지 거짓말들이 가져온 악영향을 이렇게 소개했다.
- 나쁜 코드 퍼포먼스
- 나쁜 동시성
- 나쁜 최적화 가능성
- 나쁜 안정성
- 나쁜 테스트성
여기까지 들었을 때 들었던 의문은, 저 부작용들이 과연 저 세가지 거짓말 때문에 일어나는 것들일까? 였다. 곰곰히 생각해보면, 많은 개발자들이 사랑해 마지않는 '클린XX' 개념들 중에 좋은 코드 퍼포먼스, 좋은 동시성, 좋은 최적화 가능성을 이야기 하는 것은 접해본 적이 별로 없는 것 같다. 그보단 유연하고 깔끔하고 유지보수성 높은 코드를 작성하는 것에 좀 더 치중했지 않았나? 하는 생각이다.
3. Dictionary LookUp을 구현해보세요.
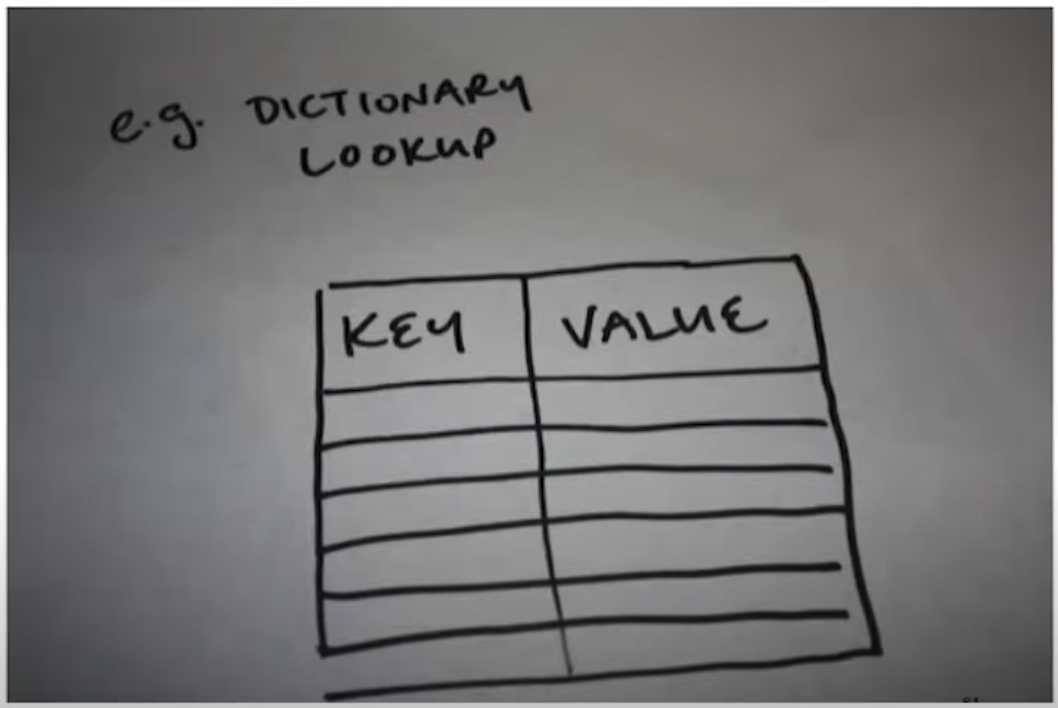
Mike는 곧바로 간단한 예시를 보여주었다. Dictionary LookUp기능을 구현하기 위한 코드를 작성할 때, 으레 개발자들은 위와 같은 그림을 머릿속에 그릴 것이다. Key-Value Pair로 구성되어 있으니 실제로 구현할 때도 메모리에 이런 모양으로 데이터 레이아웃을 구성했을 것이다. 떠오르는대로 작성해보자면 아래와 같을 것이다.
template<typename KEY_TYPE, typename VALUE_TYPE>
struct Dictionary
{
VALUE_TYPE operator[](const KEY_TYPE& key);
std::vector<std::pair<KEY_TYPE, VALUE_TYPE>> data;
};
하지만 곧바로 Mike는 이런 아이디어가 바로 위에서 말한 "Code-first Design"이며, 이러한 설계가 놓친 맹점을 바로 이렇게 짚어준다.
"Key와 Value 모두 동등한 확률로 필요할까? 아니다. 우리는 대부분의 시간을 Key 목록을 조회하는데 사용할 것이다. Value는 우리가 정말로 얻고자 하는 Key값에 대해서만 한 번 필요하다. 엄밀히 말해, Key와 Value는 개념적으로는 쌍을 이루지만 실질적으로는 연관성이 없다."


사실 생각해보면, 우리가 Dictionary에서 무언가를 조회하는 동안에는 다른 Key에 해당하는 Value들은 전혀 궁금하지 않다. 도서관에서 원하는 책을 찾기 위해 이동하는 길에 보이는 모든 책을 다 꺼내볼 필요가 없는 것처럼, Key목록을 조회하는 동안 캐시라인 위에 Value들까지 올릴 필요가 전혀 없다는 뜻이다.
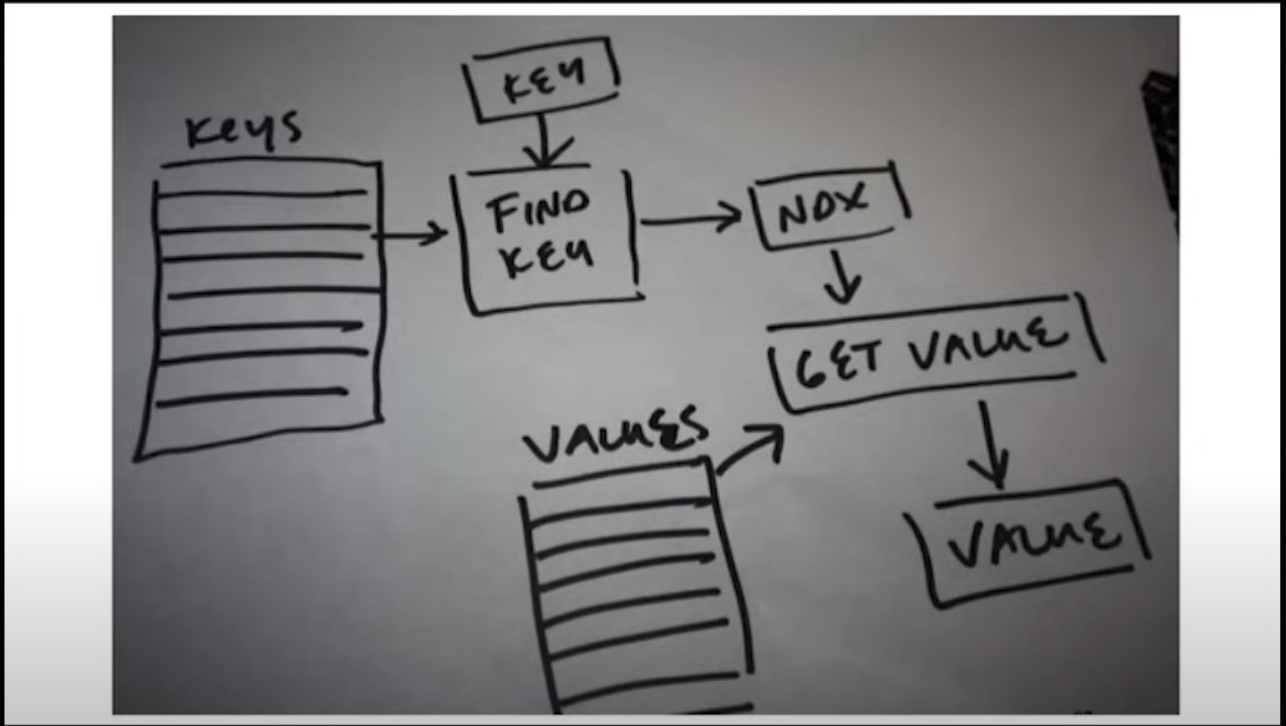
"Code-first Design"이 아니라 "Data-first Design"을 한다면, 실제로 Dictionary의 메모리는 이렇게 생겨야 한다는 뜻이다. 이렇게 하면 CPU 캐시 상에 Value들은 올라올 일이 없고, 적절한 Index가 정해진 시점에만 한 번 로드되기 때문에 훨씬 효율적인 코드가 된다는 주장이다.
template<typename KEY_TYPE, typename VALUE_TYPE>
struct Dictionary
{
VALUE_TYPE operator[](const KEY_TYPE& key)
{
return values(keyToIndex(key));
}
int keyToIndex(const KEY_TYPE& key);
std::vector<KEY_TYPE> keys;
std::vector<VALUE_TYPE> values;
};
4. "플랫폼에 대한 이해가 중요하다."
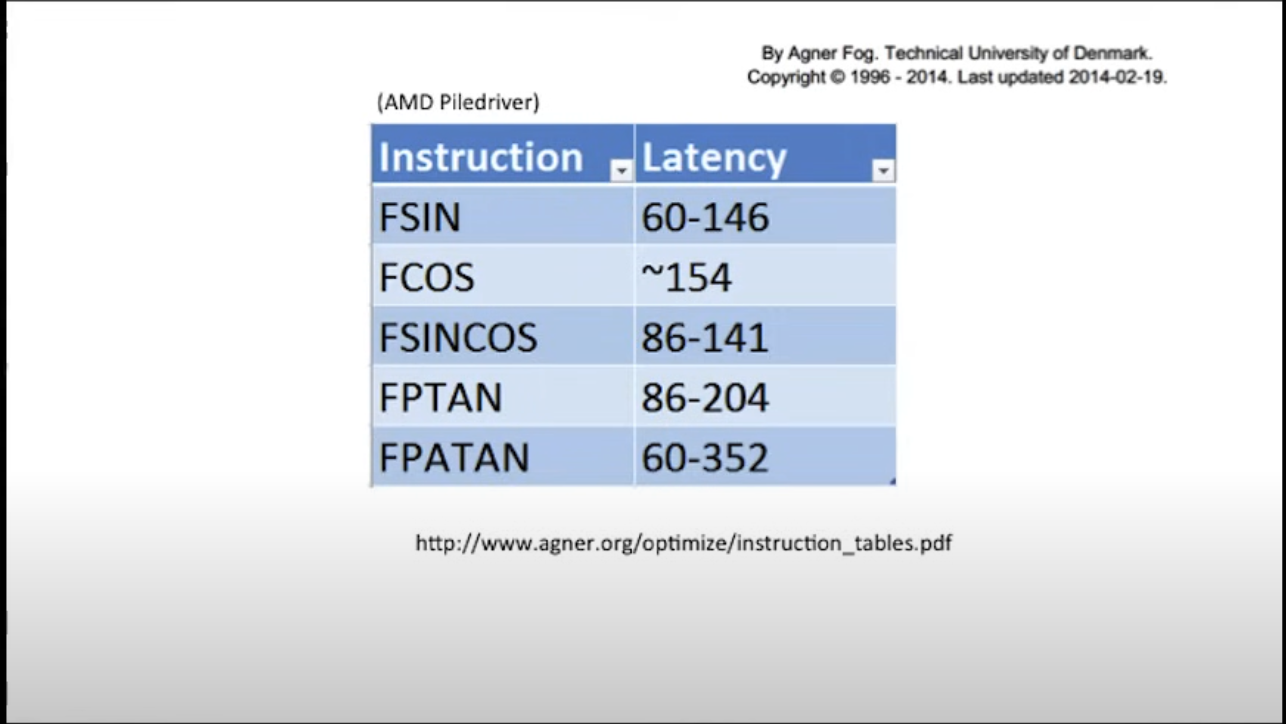
여기까지는 그럭저럭 따라올만 하다고 생각했는데, Mike가 갑자기 CPU CYCLE표를 보여주니 다소 당황스럽다. 그러나 그는 정신 차릴 시간을 주지 않고 폭주기관차처럼 설명을 이어간다.
위의 표는 AMD cpu에서 sin, cos, tan 같은 삼각함수연산을 위한 명령어가 실행되는데 걸리는 시간을 나타낸다. 여기서 말하는 Latency란 CPU CYCLE을 의미한다. 즉 위의 표에 의하면 AMD에서 Float point Sin 함수를 연산하는데 일반적으로 60~146 CYCLE를 소모한다고 한다. 밑도끝도 없이 갑자기 이 표를 왜 보여주지? 라고 생각했을 때 곧바로 본론으로 넘어간다.


위의 표에 의하면, L1 캐시에 있는 메모리에 접근하는 것은 고작 3 CYCLE밖에 들지 않지만, 기존의 캐시라인으로부터 물리적으로 멀리 떨어진 주소의 메모리에 접근을 시도하면 와장창 캐시 미스가 발생하여 Main Ram까지 다녀오는데 200+ CYCLE이 소요된다. 위의 삼각함수 연산에 드는 비용이 140 사이클 정도 이내인 것을 고려하면 상당히 무거운 비용이라고 할 수 있다.
위의 Dictionary 예제에서 만약 VALUE_TYPE이 큰 사이즈의 타입이라면, Data-Oriented Design으로 설계하지 않은 코드에서는 Key를 조회하는 매 Iteration마다 캐시 미스가 발생, 즉 200+CYCLE의 연산량을 소모할 것이다.
이 슬라이드를 보며 지난날의 과오를 되돌아보니 내가 CPU에게 저지른 죄가 너무 많아 정신이 아득해진다.

정신을 추스를 겨를도 없이, 이번엔 좀 더 강한 팩트 폭행이 가해진다. 위의 코드는 일반적으로 게임엔진에서 많이 사용되는 코드이다. 코드를 보아하니 2차원 공간에서 위치와 속도를 지닌 객체에 대해 모델링한 것으로 보인다. 그런 다음 UpdateFoo함수를 보면 m_Foo라는 어떤 magnitude 값을 계산하는 함수가 있는 것을 볼 수 있다. 이런 디자인은 거의 대부분의 GameEngine에서 볼 수 있는 디자인이다. 이 클래스만 보면, GameObject가 어떤 프로퍼티를 가지고 있고 어떤 기능들을 가지고 있는지 한 눈에 알아볼 수 있다. 아주 잘 짜여진 코드라고 . 할 수 있겠다. "Code-First Design"에서는 말이지.
자 이제 이런 가정을 해볼 수 있다. 이 GameObject 사이즈는 최소 60 byte쯤 될 것이다. m_Name과 m_Foo 사이에 훨씬 더 많은 멤버가 선언되어 있다면 그보다 훨씬 커질 수도 있다. 하지만 여전히 m_Foo는 객체의 시작점에서 가장 멀리 떨어진 주소에 있을 것이다. 그러면 이제 아래의 UpdateFoo함수를 기계어로 번역한 결과를 보자.
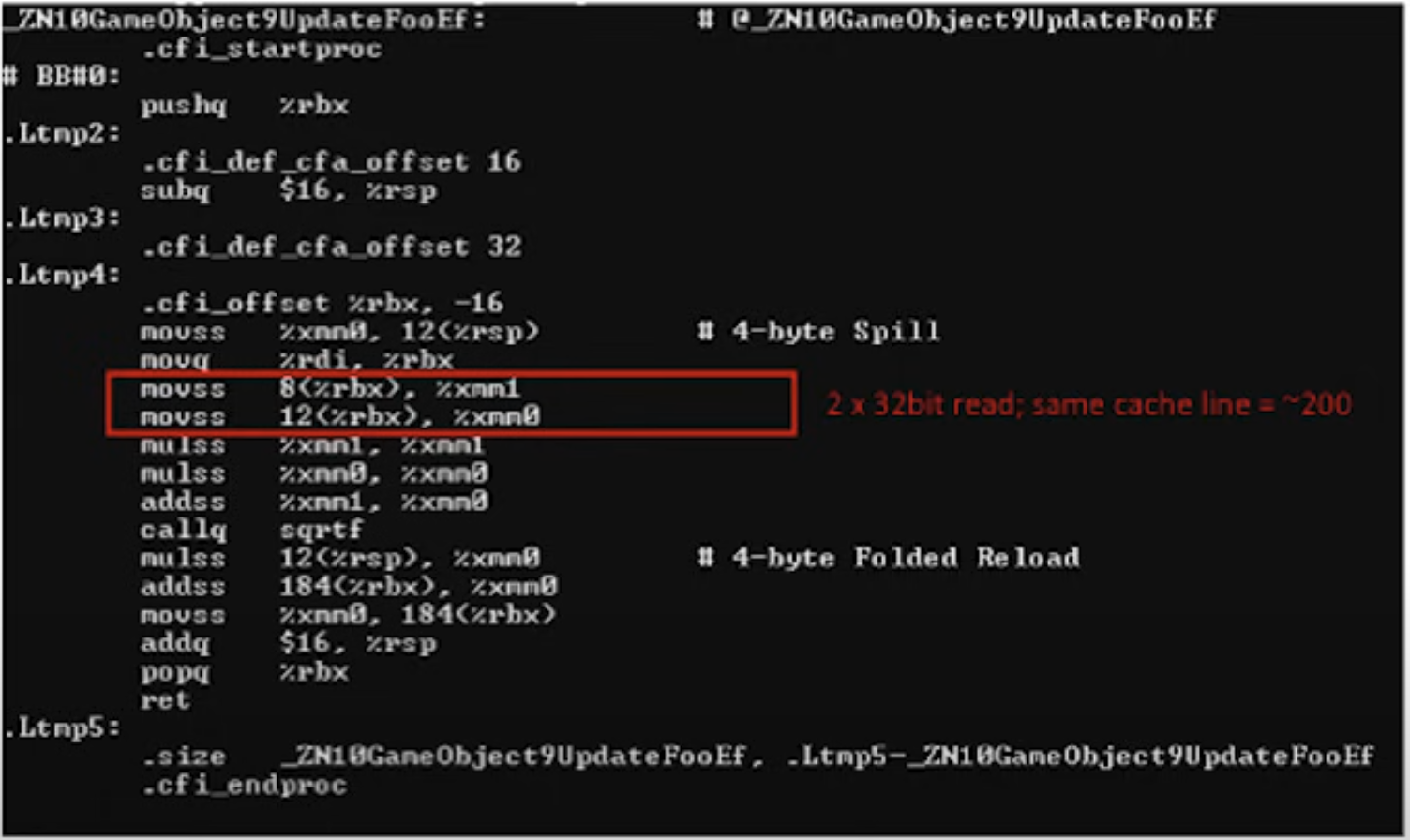
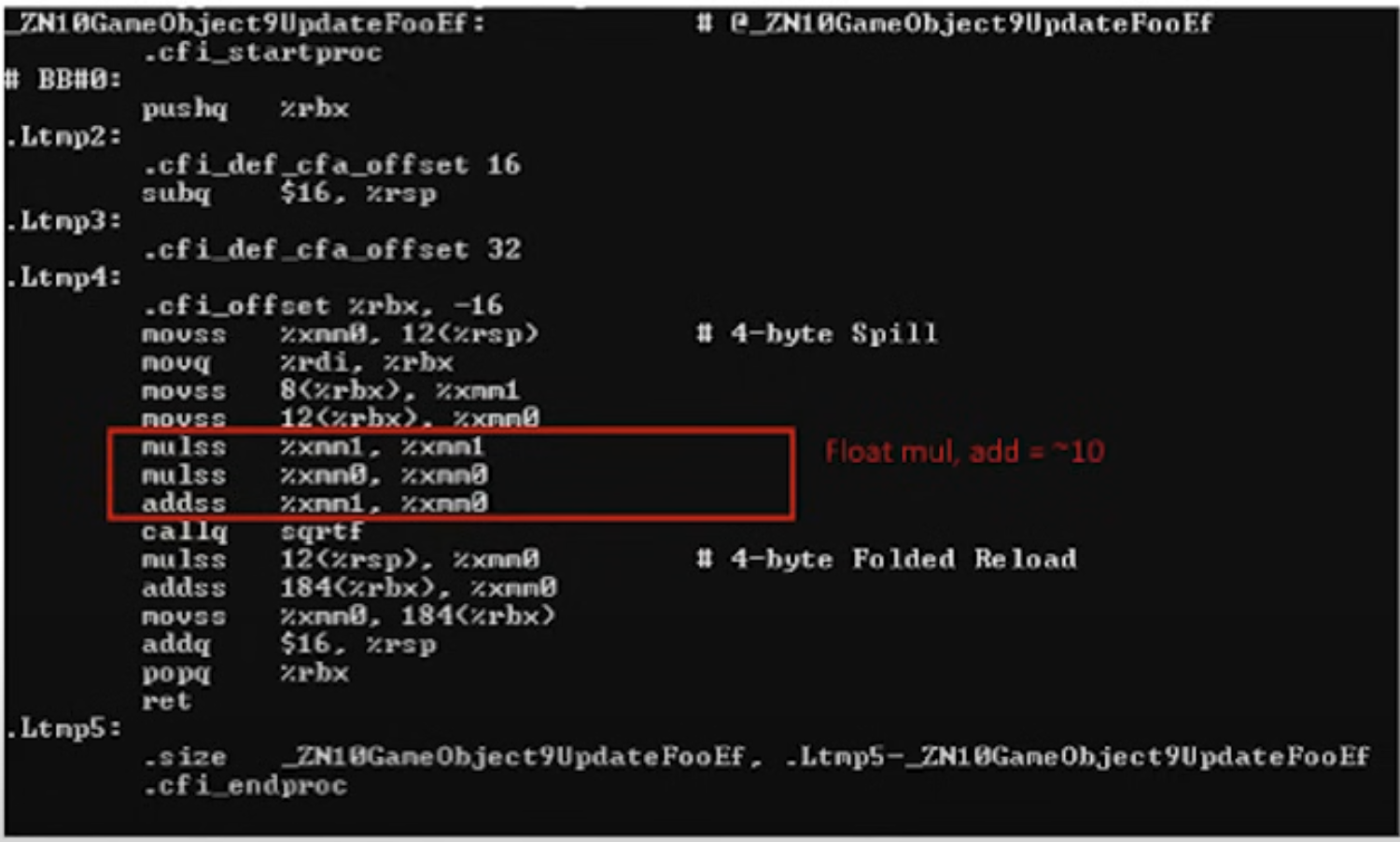
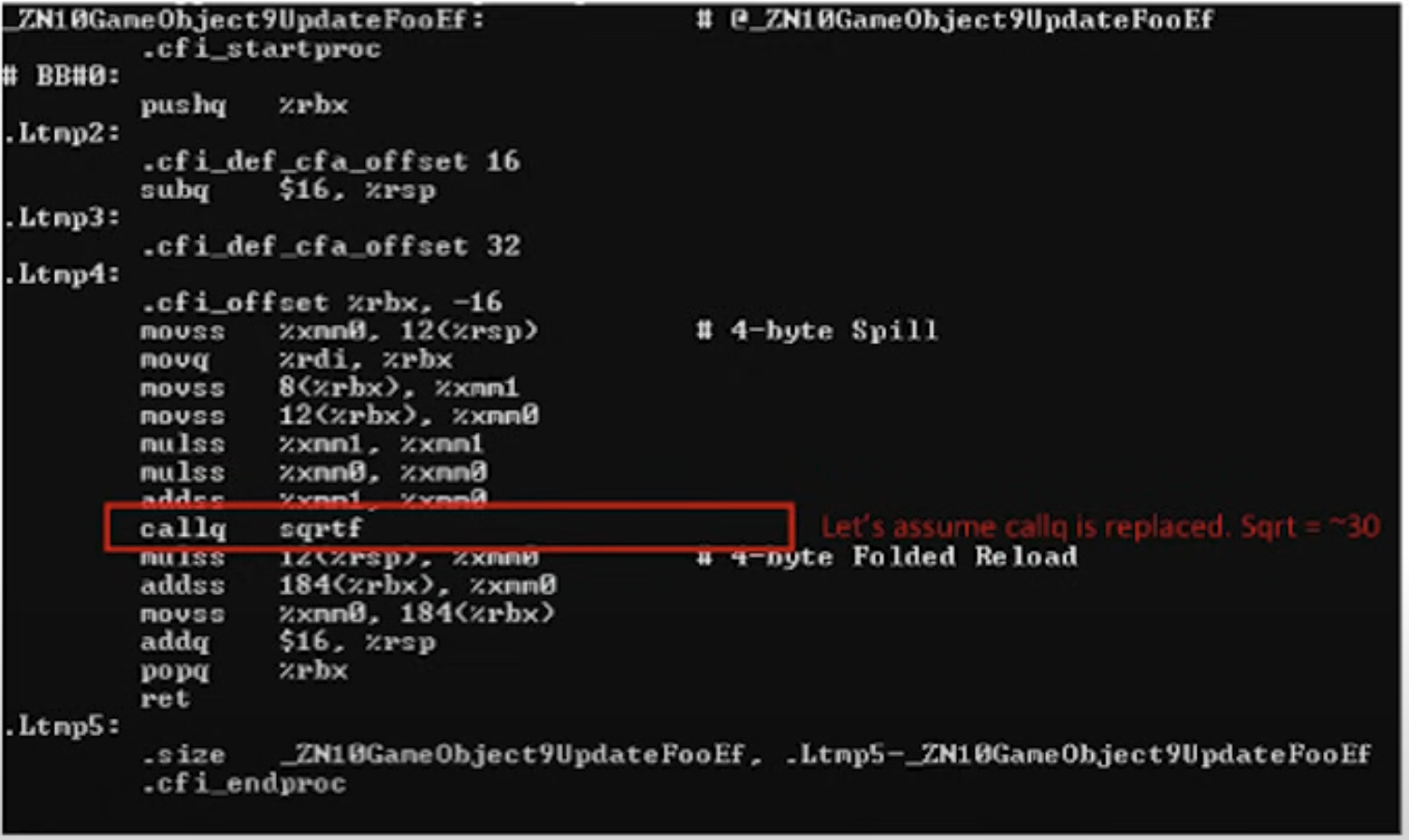
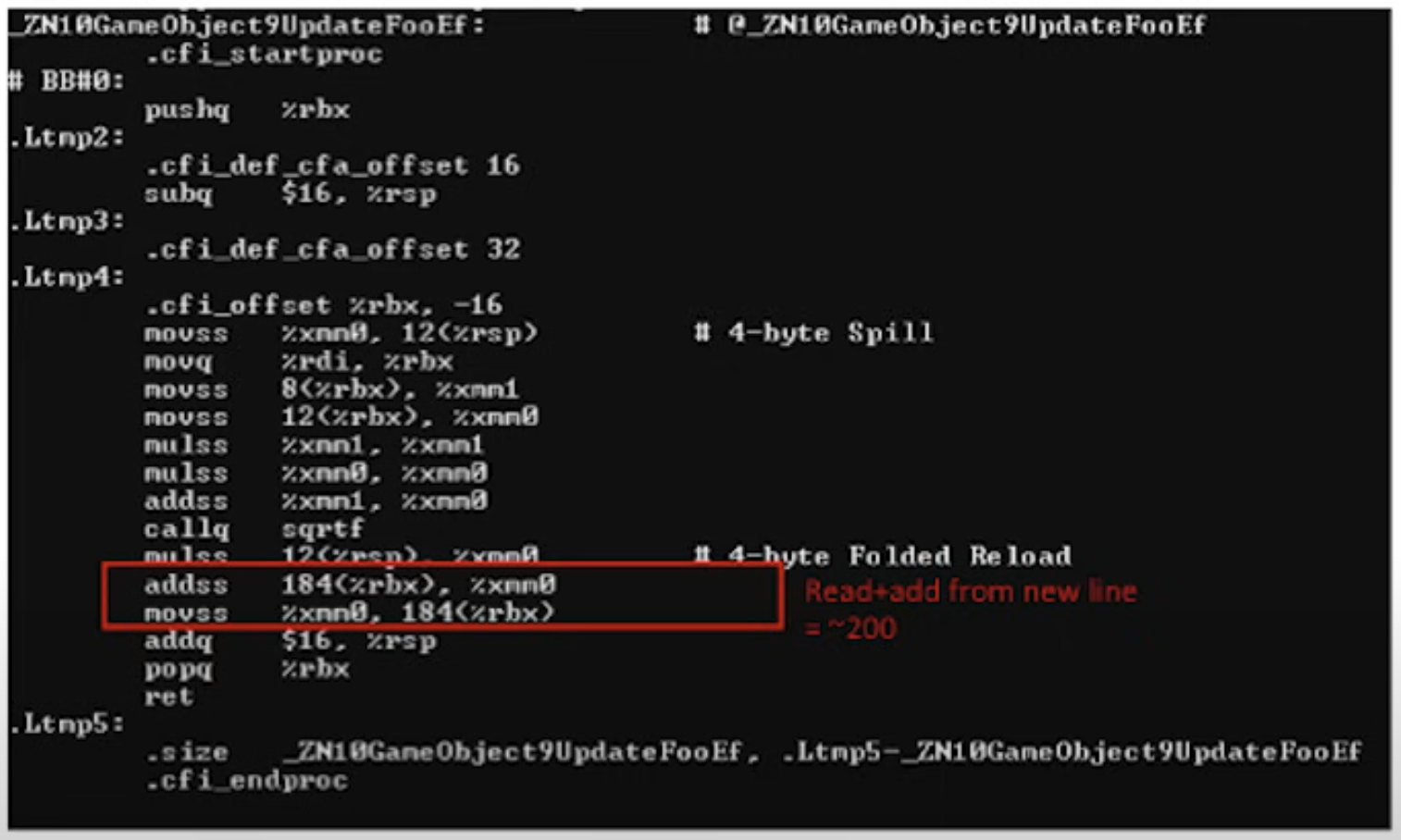
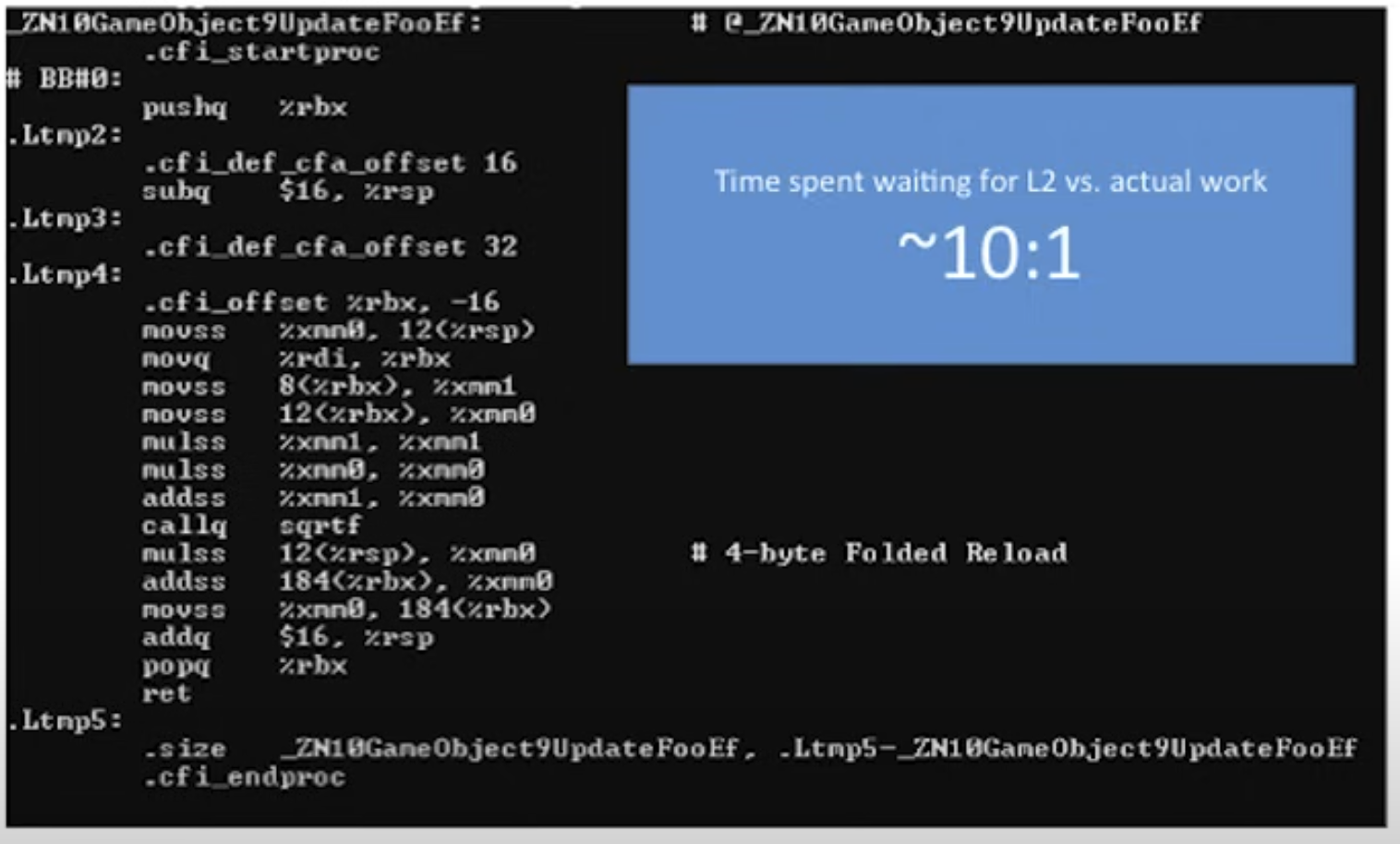
즉 UpdateFoo 함수에서 실제 중요한 로직을 수행하는데는 40cycle이지만 필요한 데이터를 로드하는 데에는 400 cycle이 소모되었다.
이렇게 숫자로 놓고보면 정말 어마어마한 낭비가 아닐 수 없다.
그런데 게임에는 GameObject가 십수개 있는 것이 아니라 천개 만개씩 존재하기도 한다. 엄청난 규모의 Scene에서는 한 번에 10만개 가량의 GameObject가 존재할 수도 있다. 그런 상황에서도 만약 GameObject 구조체가 위와 같이 설계되어 있다면, 이런 종류의 연산을 할 때마다 실제로 전체 문제에서 CPU 자원은 10%밖에 활용을 못한다는 뜻이다.

이 또한 컴파일러님께서 다 알아서 해주지 않을까 희망을 품는 불경한 자들을 위해 Mike는 이렇게 덧붙인다. 컴파일러 기술이 아무리 나날이 발전한다 하더라도, 코드 상에 선언된 클래스 구조까지 최적화 해주지는 못한다. 아무리 컴파일러가 열심히 최적화 해준다고 하더라도, 여기서는 전체 문제의 10% 내외에서만 그 능력이 발휘된다는 뜻이다.
5. Code-first가 이렇게나 위험합니다.
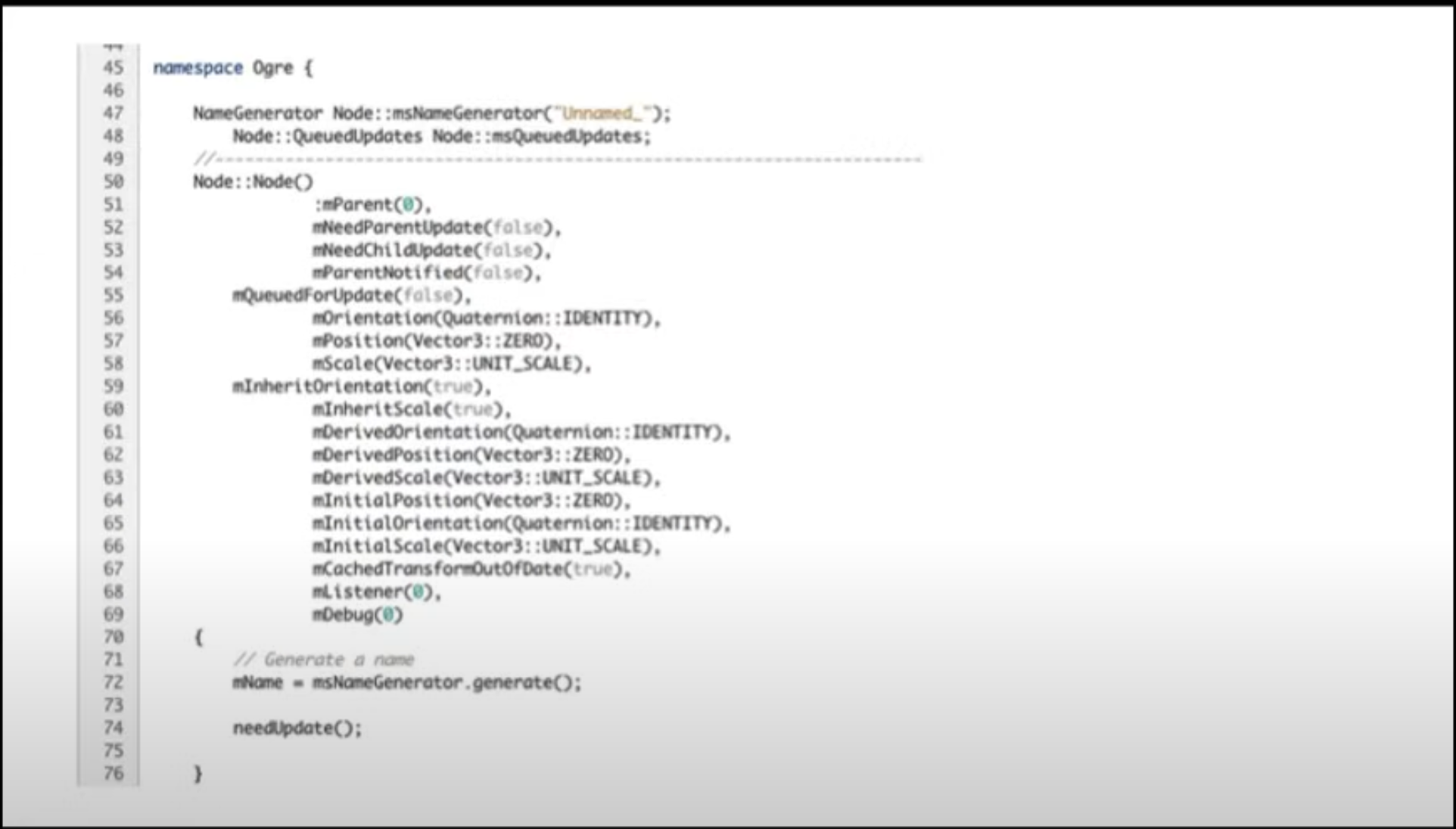
슬라이드의 후반에서는, Mike는 주저없이 유명한 오픈소스 게임엔진인 Ogre의 클래스 구조를 적나라하게 고발한다. Node는 일종의 GameObject 클래스인데, 여기에는 총 5개의 문제가 있다고 지적한다.
1) Cant' re-arrange memory
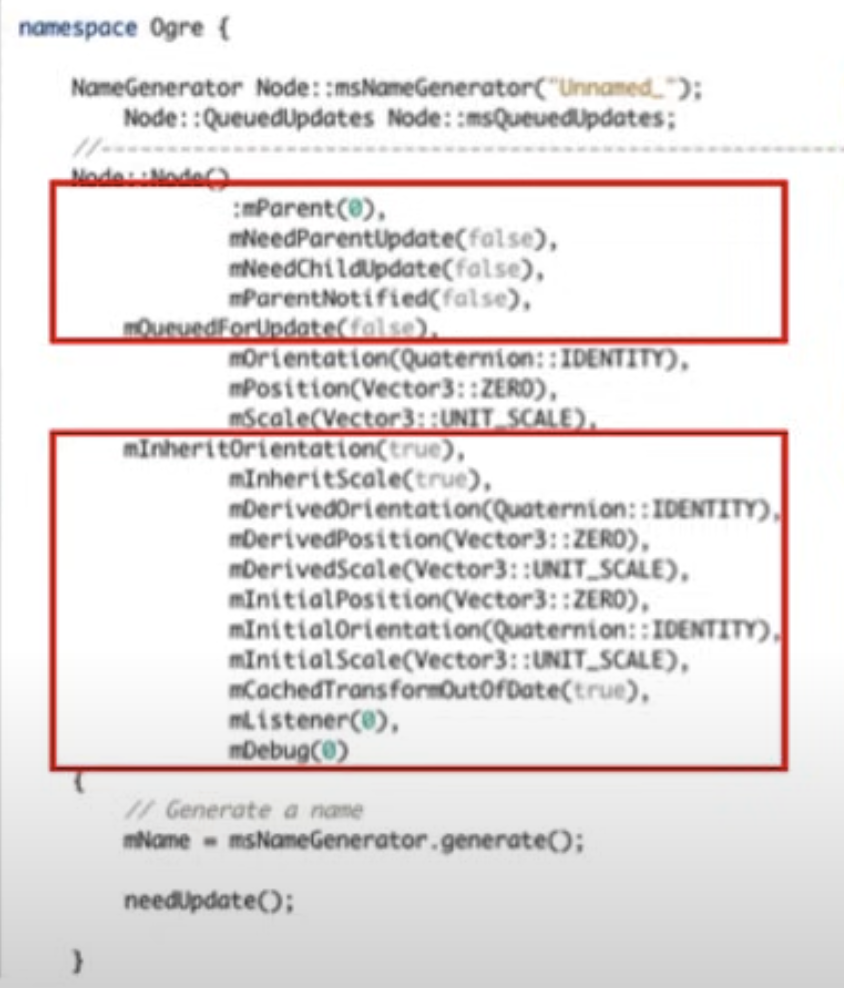
이렇게 정의된 멤버 변수들은 메모리 액세스 패턴을 예측하기가 매우 어렵기 때문에 컴파일러에서 re-arrange를 시도조차 할 수 없다. 무엇이 자주 읽혀지고 무엇이 자주 쓰여지는지, 이렇게 객체의 모든 멤버 변수가 한 번에 선언되어 있는 상황에서 컴파일러가 할 수 있는 것은 제한 적이다.
2) Bools and last-minute decision making
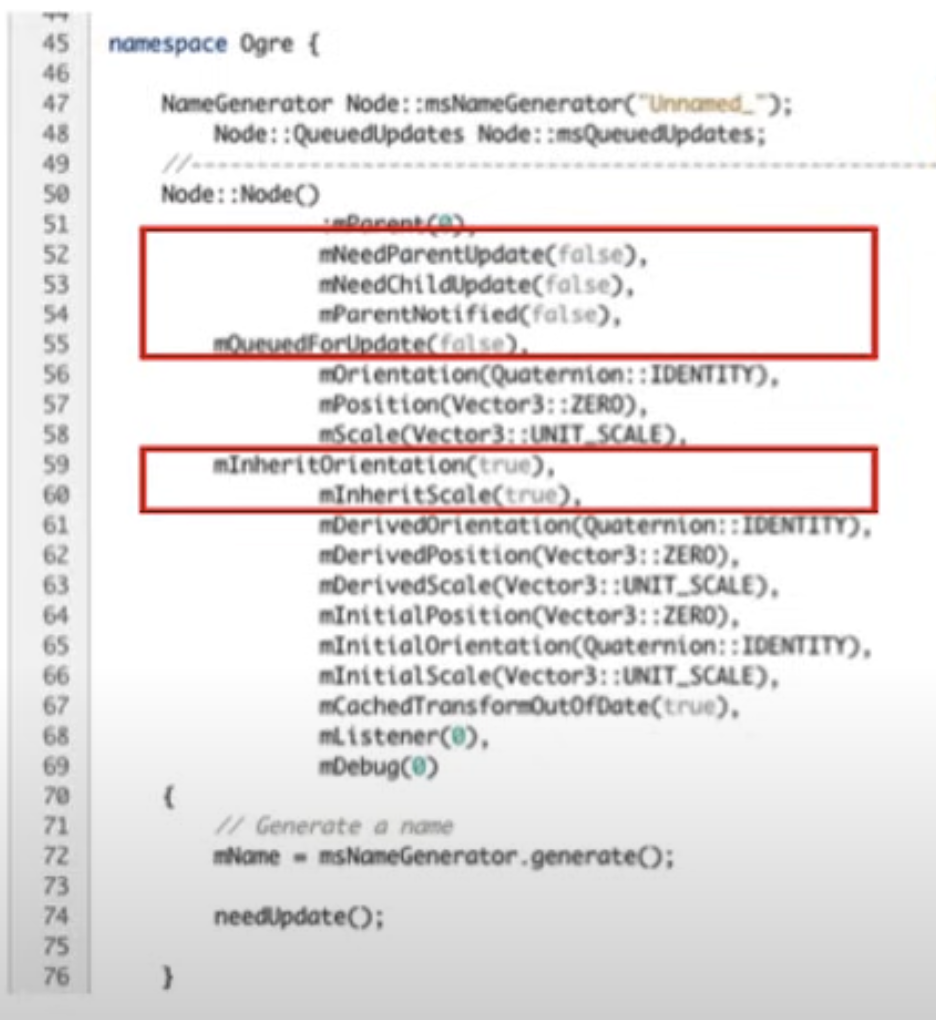
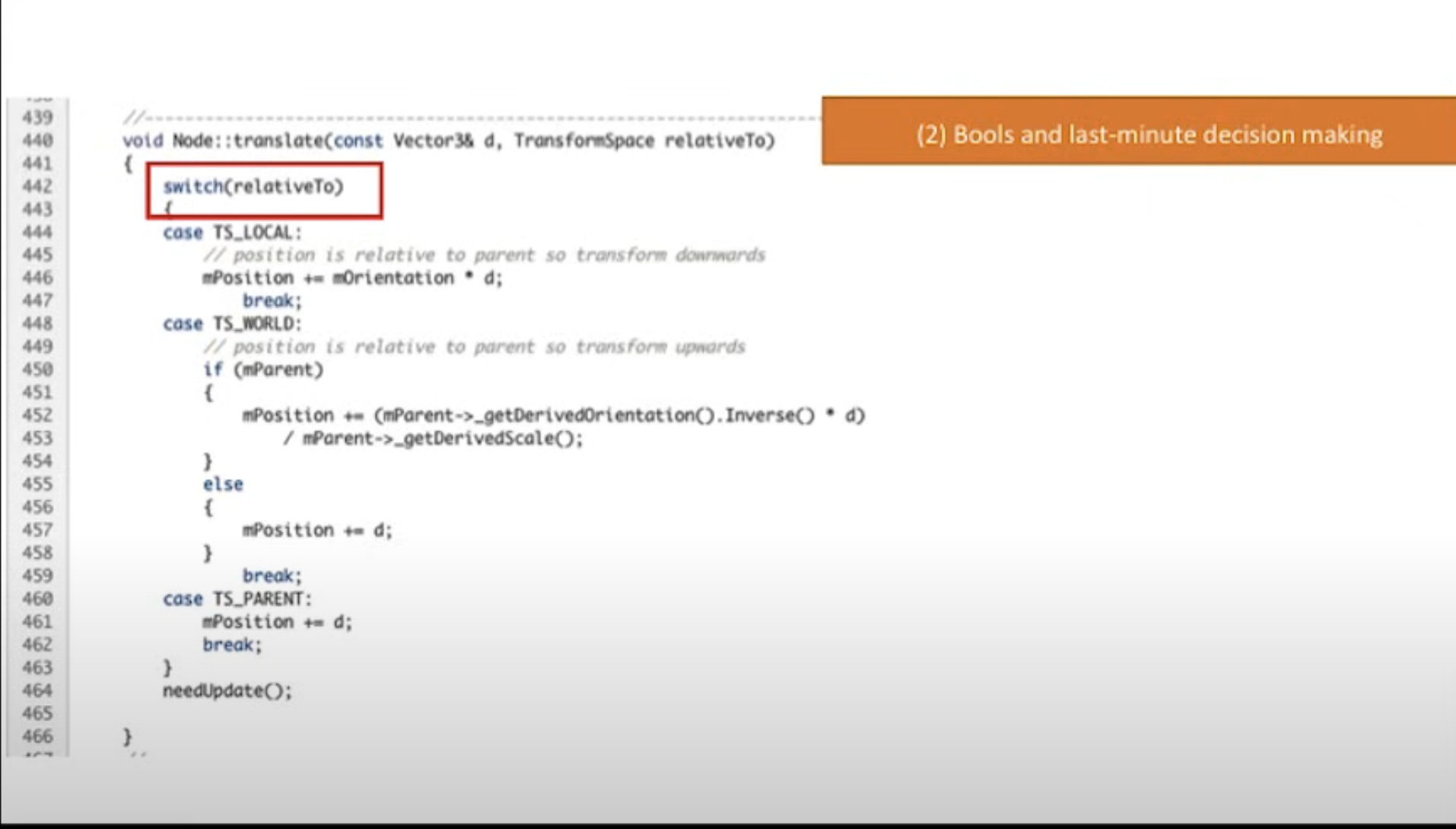
Node라는 객체는 GameObject이기 때문에 실제로 상당히 많은 숫자의 Instance가 한 번에 존재할 것이다. 그리고 개별 GameObject마다 동작유형, 관리 방식 등등도 모두 다를 것이다. 표시된 변수 이름들이 아마 이런 것들을 제어하기 위한 Boolean Flag 값일 것이다. 문제는 이 정보가 Node 인스턴스 안에 있다는 것이다. 따라서 어떤 Node가 어떻게 동작할 것인지는 실제로 그 Node의 메모리에 직접 접근해서 까봐야지만 즉, Last-minute에서야 알 수 있다는 뜻이다.
위에서 예시로 Dictionary LookUp을 예로 들자면 Value가 자신과 매칭된 Key값을 들고 있어서, Dictionary 조회를 할 때 모든 Value를 다 까보면서 Key가 매칭되는지 확인하는 것과 마찬가지라는 뜻이다.
3) Over-generalization

지나치게 일반화 되어서 객체 하나가 너무 많은 역할을 담당하고 있는 것이 문제라고 주장한다.
1. 많은 Property들로 인해 Property들에 대한 read/write를 효율적으로 관리하기가 어려워질 것이다.
2. 생성자와 소멸자에서 불필요한 read/write가 일어날 것이다.
3. 가상함수가 많아지기 때문에 vtable 참조가 많아지면서 I-cache 역시 효율적으로 관리되지 못할 것이다.
4. 객체가 가질 수 있는 State가 기하급수적으로 복잡해진다. 여기 존재하는 Boolean Flag만으로도 2^7 개 이상의 State를 가질 수 있다.
4) Undefined or under-defined constraints

생성자에서 mName 멤버는 msNameGenerator.generate()라는 함수에서 생성한 것을 그대로 받아서 할당한다. 변수명에서 유추할 수 있듯이 String은 길이 자체도 가변적인데, generator라는 함수가 넘겨주는 값이 어떤 것일지 이 코드에서는 도저히 예측할 수가 없다. 매우 우 긴 이름을 가지고 있다면 이 Node는 다른 Node들에 비해 훨씬 큰 메모리를 차지할 가능성이 존재한다. Mike는 이런 이유 하나만으로도 객체 Instance에 String 멤버 변수를 사용하는 것은 '일반적으로 나쁘다' 라고 덧붙인다.
5) Over-solving
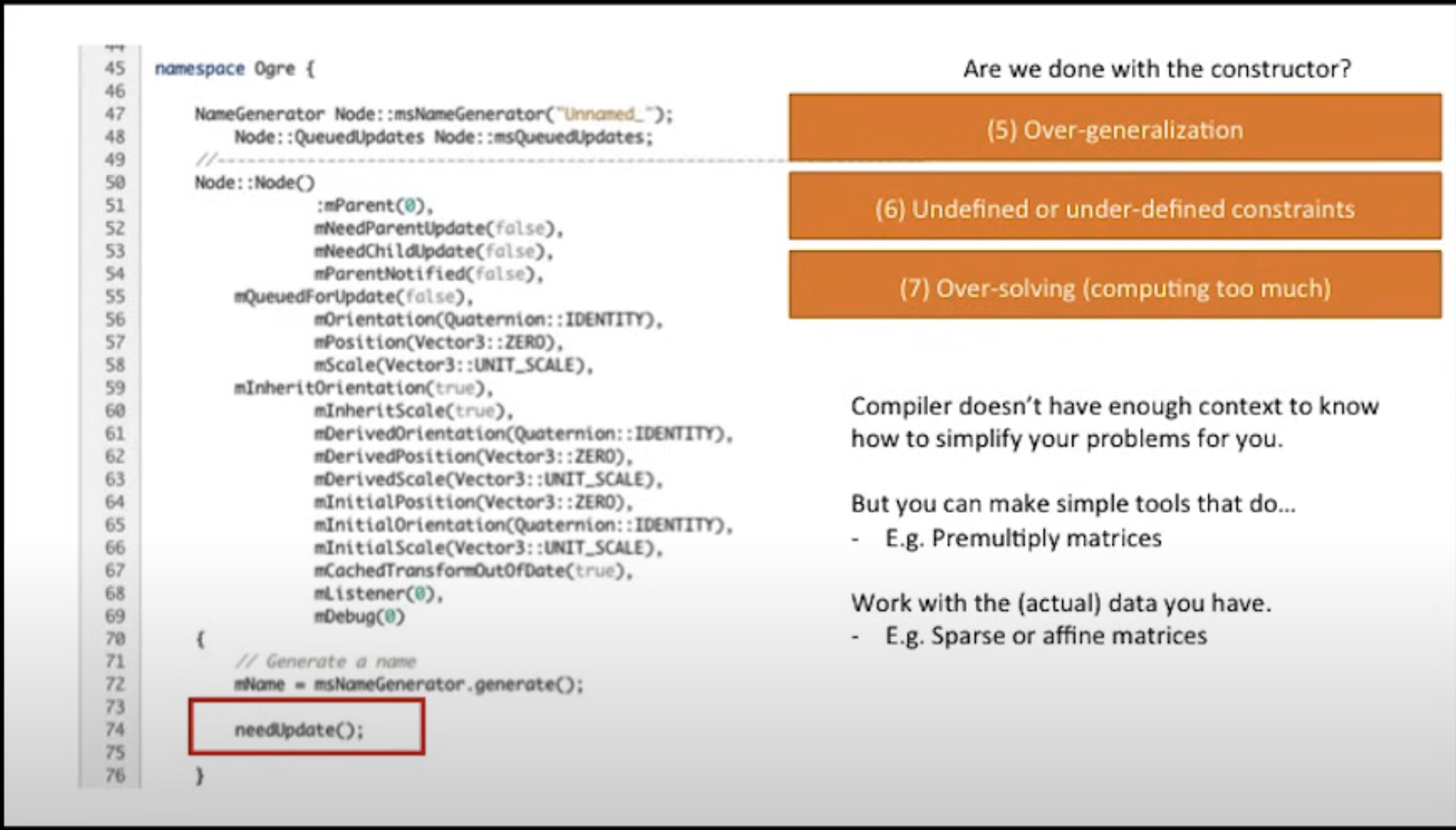
마지막 한 줄까지도 남김없이 탈탈 털린다. 대체로 needUpdate 함수는 이 인스턴스가 가진 멤버들이 최신화되어야 한다고 flag를 켜주거나 최신화를 수행하는 함수이다. 그런데 초기화 시점에 반드시 최신화가 필요할까? 생성자에서 초기화된 값 그 자체로도 최신상태일 수도 있지 않을까? 아무튼 알잘딱으로 잘 해줬으면 하는 개발자의 얕은 뜻을 컴파일러는 깊이 알지 못한다.
6. 우리는 어떻게 해야 하나요?
훌륭한 오픈소스 게임엔진인 Ogre를 뼛속까지 탈탈 터는 장면을 눈앞에서 목도했을 때 참석자들의 표정까지 화면에 담기지는 않았겠지만, 아마 모두가 망연자실한 표정이었을 것이다. Mike는 이들을 위해 위에서 지적한 문제들에 Data-Oriented Design 관점에서 어떻게 재설계할 수 있는지도 친절하게 정답을 알려준다. 그것까지 이 글에 담기에는 내용이 매우 많기 때문에귀찮고 영상을 통해 직접 확인하기를 바란다.

끝으로, Mike는 앞서 소개 했던 세 가지 거짓말들에 대해서 다음과 같이 진실을 바로잡으며 마무리한다.
* 하드웨어가 여러분의 플랫폼입니다.
* 이상적인 세계를 모델링 하지 마세요. 실제로 다루려는 데이터 자체에 집중하세요.
* 당신은(프로그래머로써) 데이터를 가공하는 것에 책임이 있지, 좋은 코드를 작성하는 것에 있지 않습니다.
7. 마치며
Data-Oriented Design의 효용성과 실용성에 대해서는 여전히 의견이 분분할 것이다. 그러나 이 발표자가 자신이 주장하는 바와 개념에 대해서 화두를 던지고 결론까지 도달하는 발표자의 논리 전개 과정은 그 누구도 토달 수 없도록 현실에 기반하여 실증적으로 진행되었다. 나도 꽤나 성능에 민감한 개발자에 속하고, 하드웨어 성능을 극한까지 끌어올리는 것을 좋아하지만 이 사람은 그 이상이었다. 발표를 끝까지 봤을 때 CPU로 하는 한 편의 차력쇼를 보는 느낌이라고 할까.


끝으로 20분에 걸친 질의응답 세션도 정말 예술이다. “이건 data-oriented가 아니라 Cache-oriented design 아닌가요?”라거나 “당신 C++개발자가 맞기는 한가? 대부분 C아니면 어셈블리어들인데?” 같은 공격적인 질문들도 더러 있었다. 하지만 그는 시종일관 단단하고 확신에 찬 어조로 답변하곤 했다.
그의 말 중에 가장 인상 깊었던 것은, "알아요. 하지만 저는 어딘가에서 이런 것들을 신경쓰는 엔지니어들도 있다는 사실을 알리고 싶었습니다." 라는 말이었다. 이토록 자신의 업에 대한 확고한 철학과 신념은 어디에서 나오는 것일까? 새삼 존경스러운 마음이 일었다.
'개발 > C++' 카테고리의 다른 글
| 첫 걸음부터 시작하는 Data Oriented Design과 C++ (1) | 2024.09.30 |
|---|



